The Challenge —
Our client required a large external data source with over 20 million records to be polled every month for refreshing the data and insourcing the updated data after normalisation.
The Solution —
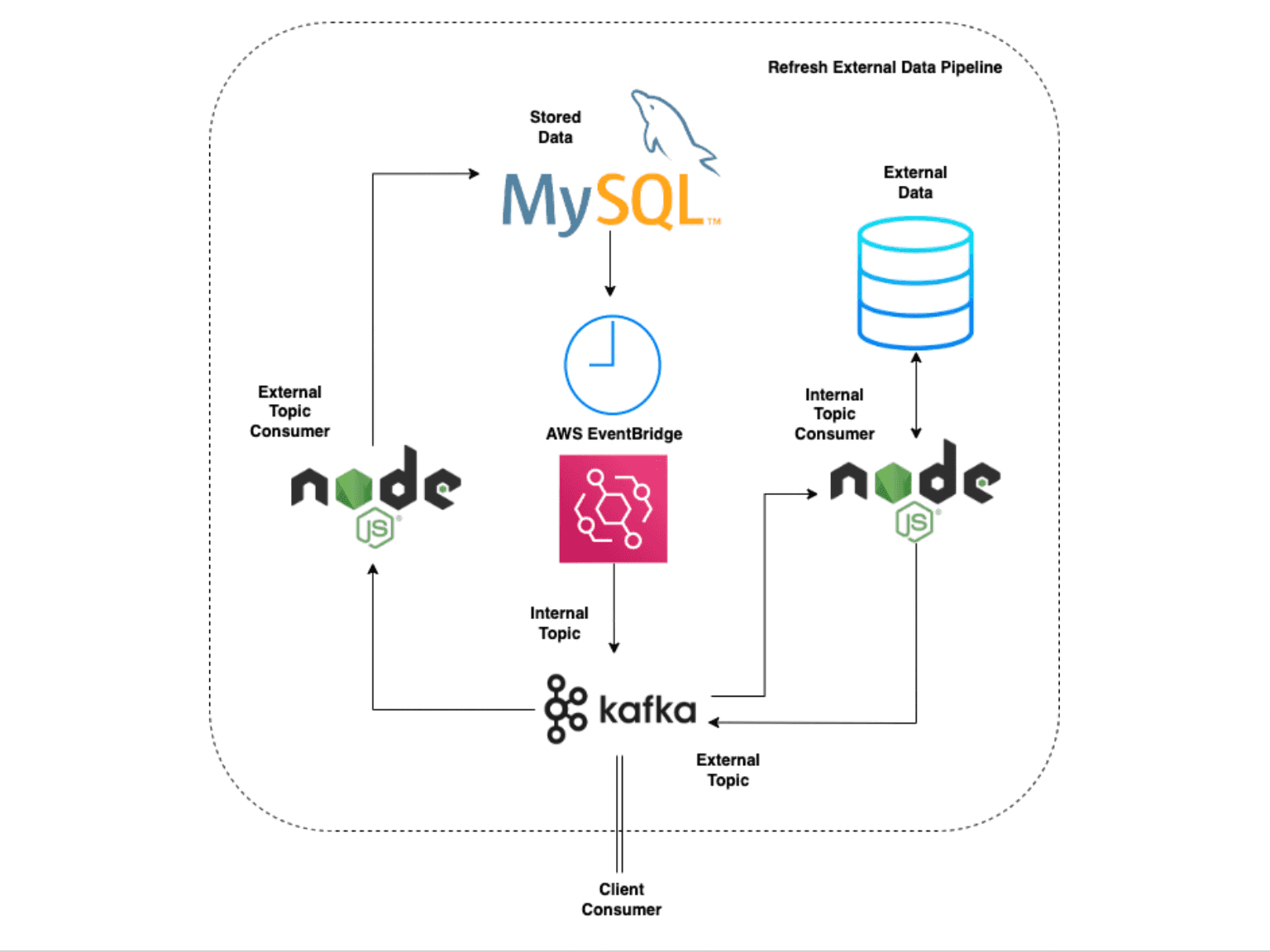
Our team built a message queue system with the pub/sub architecture. We used Kafka to poll the external data source, normalise the updated data and publish it to the client’s systems. We implemented the pipeline using three AWS services : MSK (Managed Service for Kafka), EventBridge and Batch. We then built a horizontally scalable infrastructure unit (IU), consisting of a fixed set of resources, with a fixed running cost for every IU.Through an industry standard documentation, we ensured the product would integrate seamlessly with the pipeline at the clients’ end. We scaled the pipeline to run sufficient parallel IUs as per the client’s requirements for data refresh.
Impact —
AppDesk built and deployed a highly scalable pipeline with a monthly running cost of only $50 per Infrastructure Unit deployed.
Technologies Used